AcousticBrainz Genre Task 2017: Content-based music genre recognition from multiple sources
Announcements
- Sep 11: Evaluation Results are available for all submitted runs.
- Jul 7: Evaluation summaries for random baselines are available.
- Jun 27: Evaluation scripts are available in the GitHub repository (accessible to registered participants)
- May 11: It took us extra time to process and organize our very large amounts of data. We are almost ready to release development and test datasets within a few days!
Tentative Task Schedule
- May 18th: Development and test datasets released on May 18, 2017
- June: Release of a baseline approach
- May-Mid-August: Work on algorithms
- Mid-August: Submit runs
- 14-20 August: Run submission
- 21 August: Results returned to participants
- Early September: Working notes paper due
- 13-15 September MediaEval 2017 Workshop in Dublin
Task description
This task invites participants to predict genre and subgenre of unknown music recordings (songs) given automatically computed features of those recordings. We provide a training set of such audio features taken from the AcousticBrainz database [1] together with four different ground truths of genre and subgenre labels. These genre datasets were created using as a source four different music metadata websites. Their genre taxonomies vary in class spaces, specificity and breadth. Each source has its own definition for its genre labels meaning that these labels may be different between sources. Participants must train model(s) using this data and then generate predictions of genre and subgenre labels for a test set.
We provide a dataset (a development and test set) for every genre ground truth. In total, participants will be given four development datasets and all proposed models will be evaluated on four test datasets. The goal is to create a system that uses provided music features as an input and predicts genre and subgenre labels, following genre taxonomy of each ground truth.
Importantly, annotations in the datasets are multi-label. There may be multiple genre and subgenre annotations for the same music recording. It is guaranteed that each recording has at least one genre label, while subgenres are not always present.
The task includes two subtasks:
- Subtask 1: consider each genre ground truth individually to generate predictions for the four test datasets. This subtask will serve as a baseline for Subtask 2.
- Subtask 2: combine genre ground truths together to generate predictions for the four test datasets.
Participants are expected to create models and submit their predictions for both subtasks. In the case they only want to work on Subtask 1, the same predictions will be used for evaluation in the Subtask 2.
Below is a detailed description of the subtasks.
Subtask 1: Single-source Classification. This subtask will explore conventional systems, each one trained on a single dataset. Participants will submit predictions for the test set of each dataset separately, following their respective class spaces (genres and subgenres). These predictions will be produced by a separate system for each dataset, trained without any information from the other sources.
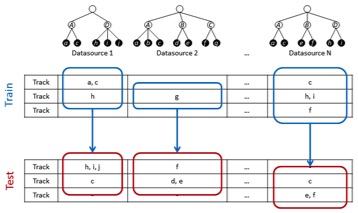
Subtask 2: Multi-source Classification. This subtask will explore how to combine several ground-truth sources to create a classification system. We will use the same four test sets. Participants will submit predictions for each test set separately, again following each corresponding genre class space. These predictions may be produced by a single system for all datasets or by one system for each dataset. Participants are free to make their own decision about how to combine the training data from all sources.
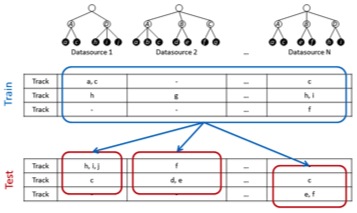
Data
We provide four datasets containing genre and subgenre annotations extracted from four different online metadata sources:
-
AllMusic and Discogs are based on editorial metadata databases maintained by music experts and enthusiasts. These sources contain explicit genre/subgenre annotations of music releases (albums) following a predefined genre namespace and taxonomy. We propagated release-level annotations to recordings (tracks) in AcousticBrainz to build the datasets.
-
Lastfm and Tagtraum are based on collaborative music tagging platforms with large amounts of genre labels provided by their users for music recordings (tracks). We have automatically inferred a genre/subgenre taxonomy and annotations from these labels following the algorithm proposed in [3] and a manual post-processing.
For details on format and contents, please refer to the data webpage.
Run submission
Participants are expected to submit predictions for both subtasks. If they only want to work on the first subtask, they should submit the same predictions for the second subtask. We allow only five evaluation runs (each run includes both subtasks). In every single run, participants should submit predictions for both Subtask1 and Subtask2 in two separate files.
Each submission should include three or four TSV files for Subtask1 (one file for each test dataset, only provide three if you are not using AllMusic data) and three or four TSV files for Subtask2. Submissions should follow a format similar to the ground truth format (see data webpage):
[RecordingID] [genre/subgenre label] [genre/subgenre label] ...
Each line corresponds to an anonymized RecordingID from a test dataset and should include explicitly all predicted genre and subgenre labels.
Participants should report whether they used the whole development dataset or only its part for every submission.
Participants can ensure their submission format is correct running the provided check script (accessible to registered participants).
Evaluation Methodology
The evaluation will be carried out for each dataset separately. In particular, we will compute precision, recall and F-score as follows:
- Per recording, all labels.
- Per recording, only genre labels.
- Per recording, only subgenre lables.
- Per label, all recordings.
- Per genre label, all recordings.
- Per subgenre label, all recordings.
Note that the ground truth does not necessarily contain subgenre annotations for some recordings. Therefore, only recordings containing subgenres will be considered for the evaluation on the subgenre level. An example can be found in the summaries of random baselines.
Evaluation scripts are provided for development (accessible to registered participants).
Working Notes and Overview Paper
Please follow the general instructions for the working notes paper. Remember to cite the task overview paper in your working notes paper. A draft version of that paper is available here:
Recommended Reading
[1] Porter, A., Bogdanov, D., Kaye, R., Tsukanov, R., Serra, X. Acousticbrainz: a community platform for gathering music information obtained from audio. In Proceedings of the 16th International Society for Music Information Retrieval Conference. Málaga, Spain, 2015, 786-792.
[2] Bogdanov, D., Wack, N., Gómez, E., Gulati, S., Herrera, P., Mayor, O., Roma, G., Salamon, J., Zapata, J., Serra, X. ESSENTIA: an audio analysis library for music information retrieval. In Proceedings of the 14th International Society for Music Information Retrieval Conference. Curitiba, Brazil, 2013, 493-498.
[3] Schreiber, H. Improving genre annotations for the million song dataset. In Proceedings of the 16th International Society for Music Information Retrieval Conference. Málaga, Spain, 2015, 242-247.
[4] Flexer, A., & Schnitzer, D. (2009). Album and Artist Effects for Audio Similarity at the Scale of the Web. In Proceedings of the 6th Sound and Music Computing Conference. Porto, Portugal.
[5] Porter, A., Bogdanov, D., Serra, X. Mining metadata from the web for AcousticBrainz. In Proceedings of the 3rd International workshop on Digital Libraries for Musicology. New York, USA, 2016, 53-56. ACM.
[6] Pachet, F., & Cazaly, D. A taxonomy of musical genres. In Content-Based Multimedia Information Access, RIAO 2000, volume 2, 1238-1245.
Task Organizers
- Dmitry Bogdanov, Music Technology Group, Universitat Pompeu Fabra, Spain (
first.last @upf.edu) - Alastair Porter, Music Technology Group, Universitat Pompeu Fabra, Spain (
first.last @upf.edu) - Julián Urbano, Multimedia Computing Group, Delft University of Technology, Netherlands
- Hendrik Schreiber, tagtraum industries incorporated, USA
Acknowledgments
AcousticBrainz, Audio Commons and tagtraum industries
![]()
![]()
![]()
This research has received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement No 688382.